论文解析:PointNet & PointNet++
传送门
参考博客:PointNet & PointNet++ 论文解析+算法理解+复现建议(3D点云 分类+分割)
PointNet
摘要:点云是一种重要的几何数据结构。由于其格式不规则,大多数研究人员将此类数据转换为规则的 3D 体素网格或图像集合。然而,这会导致数据不必要地庞大并导致问题。在本文中,我们设计了一种直接消耗点云的新型神经网络,它很好地尊重了输入中点的排列不变性。我们的网络名为 PointNet,为从对象分类、部分分割到场景语义解析等应用提供了统一的架构。虽然简单,但 PointNet 非常高效且有效。根据经验,它显示出与最先进技术相当甚至更好的强大性能。从理论上讲,我们提供分析以了解网络学到了什么以及为什么网络在输入扰动和损坏方面具有鲁棒性。
其实该论文核心的问题概括就是:利用点云数据,并通过处理保留其排列不变性,设计一个相应的MLP处理网络,来执行 3D 形状分类、形状部分分割和场景语义解析任务。
贴一下论文的网络架构图:

网络具有三个关键模块:最大池化层作为对称函数来聚合来自所有点的信息,局部和全局信息组合结构,以及两个对齐输入点和点特征的联合对齐网络。
核心:无序化的数据结构
点云表示为一组 3D 点 {Pi| i = 1, ..., n},其中每个点 Pi 是其 (x, y, z) 坐标加上额外特征通道(例如颜色、法线等)的向量。
Q1:我们的输入是欧几里得空间中的点的子集。它具有三个主要属性:
无序:与图像中的像素阵列或体积网格中的体素阵列不同,点云是一组没有特定顺序的点。换句话说,消耗 N 个 3D 点集的网络需要对 N 保持不变!输入集按数据馈送顺序的排列。
点之间的相互作用:这些点来自具有距离度量的空间。这意味着点不是孤立的,相邻点形成一个有意义的子集。因此,模型需要能够捕获附近点的局部结构,以及局部结构之间的组合相互作用。
变换下的不变性:作为一个几何对象,学习到的点集表示对于某些变换应该是不变的。例如,一起旋转和平移点不应修改全局点云类别或点的分割
A1:无序输入的对称函数 为了使模型对输入排列不变,存在三种策略:
将输入排序为规范顺序;要求该图在维度减小时保持空间邻近性,一般难以实现,且效果不好
将输入视为序列来训练 RNN,但通过各种排列来扩充训练数据; 将元素数量扩展到数千个输入元素(常规点云数量)难以确保鲁棒性
使用简单的对称函数来聚合每个点的信息。这里,对称函数以 n 个向量作为输入,并输出一个与输入阶数无关的新向量。例如,+和*运算符是对称二元函数。
作者关注并实验比较了以上3种方法,最后以第三种方法作为解决方案。
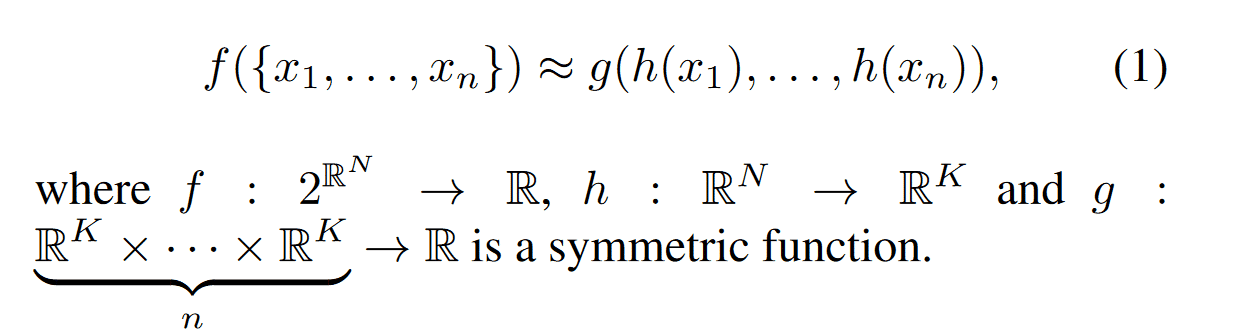
定义一组 f ,将无序点云数据映射到一组向量上。其中的 g 表示为一组对称函数。作者通过多层感知器网络来近似 h,通过单变量函数和最大池函数的组合来近似 g。通过实验发现这种方法效果很好。
")
这个核心思想是先MLP折叠成N * K维度的向量(N为点云数量)然后对N层网络取最大池化,由于最大池化和顺序并无关联(当然,取平均值,相乘这些操作也是一样的对称函数。但是实验证明是最大池化的操作在处理各种任务当中的准确率最高)。也是本文核心的网络结构。
PointNet++
摘要:之前很少有研究研究点集深度学习的作品。 PointNet 是这个方向的先驱。然而,根据设计,PointNet 无法捕获由所在的度量空间点引起的局部结构,从而限制了其识别细粒度模式的能力以及对复杂场景的泛化能力。在这项工作中,我们引入了一种分层神经网络,它将 PointNet 递归地应用于输入点集的嵌套分区。通过利用度量空间距离,我们的网络能够随着上下文尺度的增加来学习局部特征。通过进一步观察,点集通常以不同的密度进行采样,这导致在均匀密度上训练的网络的性能大大降低,我们提出了新颖的集合学习层来自适应地组合多个尺度的特征。实验表明,我们的网络 PointNet++ 能够高效、鲁棒地学习深度点集特征。特别是,在具有挑战性的 3D 点云基准上获得了明显优于最新技术的结果。
提取关键词:问题——PointNet 无法捕获由所在的度量空间点引起的局部结构,从而限制了其识别细粒度模式的能力以及对复杂场景的泛化能力。换言之在大场景下面对海量的点云无法很好捕捉局部的特征。
PointNet++ 的总体思想很简单。我们首先根据底层空间的距离度量将点集划分为重叠的局部区域。与 CNN 类似,我们提取局部特征,捕捉小邻域的精细几何结构;这些局部特征被进一步分组为更大的单元并被处理以产生更高级别的特征。重复这个过程,直到我们获得整个点集的特征。
PointNet++的设计必须解决两个问题:如何生成点集的划分,以及如何通过局部特征学习器抽象点集或局部特征。
网络结构示意图如下
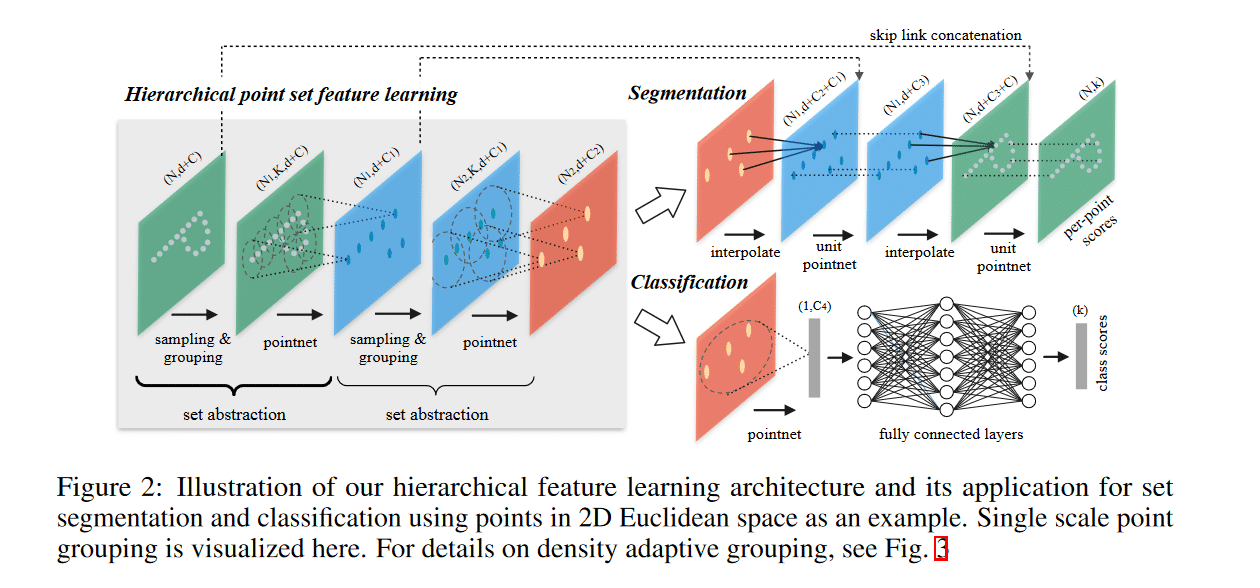
核心:SGP(采样,分组,特征编码)
这次论文改进的核心架构——Sampling layer,Grouping layer,PointNet layer。用论文的话来说是分层点集特征学习(Hierarchical Point Set Feature Learning) 构建点的分层分组,并沿着层次结构逐步抽象出越来越大的局部区域网络结构。
Sampling layer:从输入点中选择一组局部区域质心点。这里可以使用FPS(farthest point sampling)最远点采样的方法(论文方法)。解释为与随机采样相比,在质心数量相同的情况下,它可以更好地覆盖整个点集。
Grouping layer:查找质心周围的“相邻”点来构造 局部区域集(质心+“相邻”点)。可以用KNN近邻算法或者球状领域查找(本文推荐)。
该层的输入是大小为 N × (d + C) 的点集和大小为 N ' × d 的质心集的坐标。输出是大小为 N ′ × K × (d + C) 的点集组。其中每个组对应于一个局部区域,K 是质心点邻域中的点数。请注意,K 因组而异,但后续的 PointNet 层能够将灵活数量的点转换为固定长度的局部区域特征向量。
这两层的操作类比到卷积层操作上就类似创造一个特定大小的卷积核。
PointNet layer:使用mini-PointNet将局部区域模式编码为特征向量。基本上对应之前的工作了。
整个过程不断减少点的数量,同时增加通道的数量,类似CNN的结构。可以说PointNet++就相当于点云的CNN。
")
核心2:多尺度分组和多分辨率分组(MSG & MRG)
点集在不同区域的密度不均匀是很常见的。这种不均匀性给点集特征学习带来了重大挑战。在密集数据中学习的特征可能无法推广到稀疏采样区域。因此,针对稀疏点云训练的模型可能无法识别细粒度的局部结构。
为解决这一问题,文章提出了密度自适应 PointNet 层。
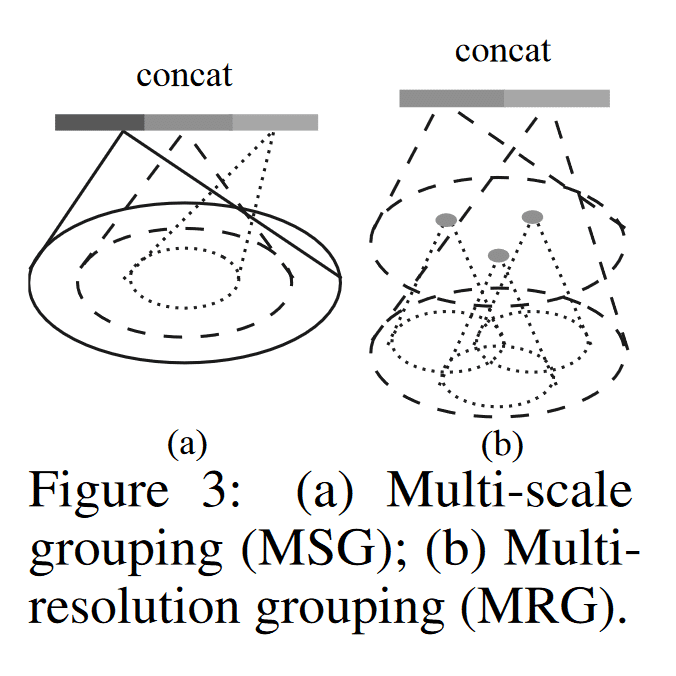
MSG:捕获多尺度模式的一种简单但有效的方法是应用不同尺度的分组层,然后根据 PointNet 提取每个尺度的特征。不同尺度的特征连接起来形成多尺度特征。
MRG:在图 3 (b) 中,某个级别 Li 的区域特征是两个向量的串联。通过使用设定的抽象级别从较低级别 Li−1 总结每个子区域的特征,获得一个向量(图中左侧)。另一个向量(右)是使用单个PointNet直接处理局部区域中的所有原始点获得的特征。
复现
这边贴的是pytorch的代码,就相当容易再现了。用的3.9版本和2开头的torch版本都可以正常运行。
代码/结构解释
知乎:PointNet++论文解析与代码详解(含特征维度变化框图和代码注释)
三线性插值这边比较特殊的感觉,如果是图形学理解就是坐标上就像做了3个维度(方向)上的中点变换。
对于网络层结构:
class PointNet2ClassificationMSG(PointNet2ClassificationSSG):
def _build_model(self):
super()._build_model()
self.SA_modules = nn.ModuleList()
self.SA_modules.append(
PointnetSAModuleMSG(
npoint=512,
radii=[0.1, 0.2, 0.4],
nsamples=[16, 32, 128],
mlps=[[3, 32, 32, 64], [3, 64, 64, 128], [3, 64, 96, 128]],
use_xyz=self.hparams["model.use_xyz"],
)
)
input_channels = 64 + 128 + 128
self.SA_modules.append(
PointnetSAModuleMSG(
npoint=128,
radii=[0.2, 0.4, 0.8],
nsamples=[32, 64, 128],
mlps=[
[input_channels, 64, 64, 128],
[input_channels, 128, 128, 256],
[input_channels, 128, 128, 256],
],
use_xyz=self.hparams["model.use_xyz"],
)
)
self.SA_modules.append(
PointnetSAModule(
mlp=[128 + 256 + 256, 256, 512, 1024],
use_xyz=self.hparams["model.use_xyz"],
)
)注意的是上面的这几个打包好的Modules对应的代码文件在pointnet2_modules.py里面,可查(pytorch版本)
在 pointnet2_modules.py 文件中,有几个主要的模块,每个模块都有明确的功能:
build_shared_mlp
- 这个函数构建一个共享的多层感知器(MLP)网络。它接受一个包含每层神经元数量的列表
mlp_spec和一个布尔值bn指示是否使用批归一化。返回一个nn.Sequential对象,包含一系列卷积层、批归一化层和ReLU激活函数。
- 这个函数构建一个共享的多层感知器(MLP)网络。它接受一个包含每层神经元数量的列表
_PointnetSAModuleBase
- 这是一个基础类,用于实现PointNet++的抽象层。它定义了核心的
forward函数,用于将输入的点云进行采样和特征提取。通过pointnet2_utils中的工具进行最远点采样((FPS)和特征聚合。
- 这是一个基础类,用于实现PointNet++的抽象层。它定义了核心的
PointnetSAModuleMSG
- 这是一个继承自
_PointnetSAModuleBase的类,实现了多尺度分组(Multiscale Grouping)的PointNet抽象层。它接收多个尺度的半径和样本数,以及每个尺度的MLP规格,构建对应的groupers和mlps。
- 这是一个继承自
PointnetSAModule
- 这是一个继承自
PointnetSAModuleMSG的类,实现了单尺度分组的PointNet抽象层。它接收单个半径和样本数,以及一个MLP规格,构建对应的groupers和mlps。
- 这是一个继承自
PointnetFPModule
- 这是一个特征传播模块,用于将已知点集的特征传播到未知点集。它接收一个MLP规格的列表
mlp和一个布尔值bn,构建一个共享的MLP网络。其forward函数实现了基于三线性插值的特征传播。
- 这是一个特征传播模块,用于将已知点集的特征传播到未知点集。它接收一个MLP规格的列表
看一些讨论区可以看到FPS这一步算是算力消耗最大的一个成分。
结合主要架构,可以按前面参考的知乎的文章画出网络的大致架构图:
PointnetSAModuleMSG(
(groupers): ModuleList(
(0): QueryAndGroup()
(1): QueryAndGroup()
(2): QueryAndGroup()
)
(mlps): ModuleList(
(0): SharedMLP(
(layer0): Conv2d(
(conv): Conv2d(3, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(normlayer): BatchNorm2d(
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU(inplace))
(layer1): Conv2d(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(normlayer): BatchNorm2d(
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU(inplace))
(layer2): Conv2d(
(conv): Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(normlayer): BatchNorm2d(
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU(inplace)))
(1): SharedMLP(
(layer0): Conv2d(
(conv): Conv2d(3, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(normlayer): BatchNorm2d(
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU(inplace))
(layer1): Conv2d(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(normlayer): BatchNorm2d(
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU(inplace))
(layer2): Conv2d(
(conv): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(normlayer): BatchNorm2d(
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU(inplace)))
(2): SharedMLP(
(layer0): Conv2d(
(conv): Conv2d(3, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(normlayer): BatchNorm2d(
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU(inplace))
(layer1): Conv2d(
(conv): Conv2d(64, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(normlayer): BatchNorm2d(
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU(inplace))
(layer2): Conv2d(
(conv): Conv2d(96, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(normlayer): BatchNorm2d(
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU(inplace)))
)
)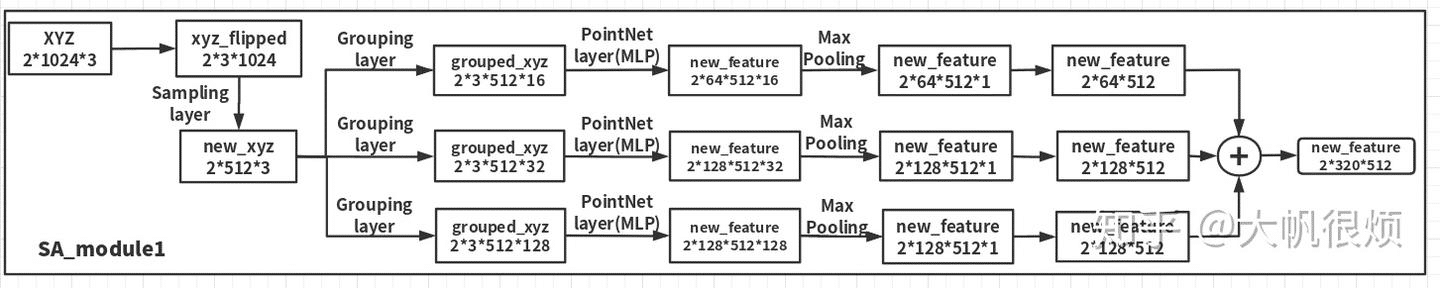
结合不同任务的变换还是参考上面知乎的那一条框图。
ATT: 在使用的时候上采样层也就是FPModule是倒着使用的, 即先从经过SA采样的最后两层进行上采样然后经过FP中间的两层卷积获得对应的特征, 然后再进行下一层的传递, 所以在使用时FPModule的运行顺序是(3)->(0).对应的输入通道数也是从最后的两层SA采样后的特征维度上进行级联的。
说白了就是作者的网络层命名顺序倒过来了。